All Categories
Featured
Table of Contents

Generative AI has organization applications beyond those covered by discriminative models. Allow's see what basic models there are to use for a large range of problems that obtain excellent results. Various algorithms and associated versions have been established and trained to develop brand-new, reasonable material from existing information. Several of the models, each with distinctive mechanisms and capacities, go to the forefront of developments in areas such as picture generation, message translation, and data synthesis.
A generative adversarial network or GAN is an artificial intelligence structure that places the 2 semantic networks generator and discriminator versus each other, therefore the "adversarial" part. The contest between them is a zero-sum game, where one representative's gain is an additional representative's loss. GANs were invented by Jan Goodfellow and his associates at the University of Montreal in 2014.

The closer the outcome to 0, the more most likely the output will certainly be fake. The other way around, numbers closer to 1 reveal a higher possibility of the forecast being genuine. Both a generator and a discriminator are usually carried out as CNNs (Convolutional Neural Networks), especially when collaborating with pictures. So, the adversarial nature of GANs depends on a game logical circumstance in which the generator network need to compete against the foe.
Ai Ecosystems
Its opponent, the discriminator network, tries to differentiate in between samples attracted from the training information and those attracted from the generator. In this situation, there's constantly a champion and a loser. Whichever network falls short is updated while its opponent continues to be the same. GANs will certainly be considered successful when a generator creates a phony example that is so persuading that it can trick a discriminator and human beings.
Repeat. It discovers to find patterns in sequential information like composed text or spoken language. Based on the context, the model can forecast the next element of the series, for instance, the next word in a sentence.
Federated Learning

A vector represents the semantic features of a word, with similar words having vectors that are close in value. 6.5,6,18] Of program, these vectors are simply illustrative; the real ones have several even more measurements.
So, at this phase, information regarding the setting of each token within a series is included the form of an additional vector, which is summarized with an input embedding. The outcome is a vector showing the word's first definition and position in the sentence. It's then fed to the transformer neural network, which contains two blocks.
Mathematically, the relations in between words in an expression resemble distances and angles in between vectors in a multidimensional vector area. This mechanism is able to find refined ways also remote data elements in a series influence and rely on each other. In the sentences I poured water from the bottle right into the cup till it was complete and I put water from the bottle into the mug till it was empty, a self-attention device can distinguish the definition of it: In the former instance, the pronoun refers to the mug, in the latter to the bottle.
is made use of at the end to calculate the possibility of different outputs and pick one of the most potential alternative. Then the generated result is appended to the input, and the entire procedure repeats itself. The diffusion model is a generative version that creates brand-new information, such as images or sounds, by simulating the information on which it was educated
Consider the diffusion model as an artist-restorer that examined paintings by old masters and now can paint their canvases in the exact same design. The diffusion version does about the very same thing in 3 main stages.gradually presents noise into the initial image up until the result is just a disorderly set of pixels.
If we go back to our example of the artist-restorer, straight diffusion is taken care of by time, covering the paint with a network of splits, dirt, and oil; occasionally, the painting is revamped, adding particular details and eliminating others. resembles examining a paint to comprehend the old master's initial intent. AI-powered advertising. The model meticulously examines just how the included noise changes the information
Ai-driven Recommendations
This understanding permits the design to efficiently turn around the procedure in the future. After learning, this version can rebuild the distorted information using the procedure called. It begins from a sound example and removes the blurs step by stepthe same method our artist gets rid of pollutants and later paint layering.
Unrealized depictions contain the essential elements of data, allowing the version to regrow the initial information from this encoded significance. If you transform the DNA particle just a little bit, you obtain a totally different microorganism.
What Are The Risks Of Ai?
As the name suggests, generative AI transforms one type of picture into an additional. This task entails removing the design from a famous painting and applying it to one more photo.
The outcome of using Secure Diffusion on The results of all these programs are quite comparable. However, some individuals note that, generally, Midjourney draws a little more expressively, and Steady Diffusion complies with the demand a lot more clearly at default settings. Scientists have actually additionally made use of GANs to generate manufactured speech from text input.
Is Ai Replacing Jobs?
The main task is to perform audio evaluation and produce "dynamic" soundtracks that can transform depending on just how individuals interact with them. That said, the songs might change according to the environment of the game scene or depending on the intensity of the individual's workout in the gym. Review our post on discover more.
So, rationally, video clips can additionally be produced and transformed in similar means as images. While 2023 was marked by innovations in LLMs and a boom in picture generation modern technologies, 2024 has actually seen substantial innovations in video clip generation. At the beginning of 2024, OpenAI presented an actually excellent text-to-video model called Sora. Sora is a diffusion-based design that produces video from fixed sound.
NVIDIA's Interactive AI Rendered Virtual WorldSuch artificially developed data can help establish self-driving automobiles as they can utilize produced virtual globe training datasets for pedestrian discovery. Of course, generative AI is no exemption.
When we say this, we do not suggest that tomorrow, machines will certainly climb versus humankind and ruin the world. Allow's be straightforward, we're respectable at it ourselves. Since generative AI can self-learn, its actions is difficult to regulate. The outcomes supplied can often be far from what you anticipate.
That's why so many are carrying out vibrant and intelligent conversational AI models that consumers can connect with through message or speech. In addition to client service, AI chatbots can supplement advertising and marketing efforts and assistance internal communications.
What Are Ethical Concerns In Ai?
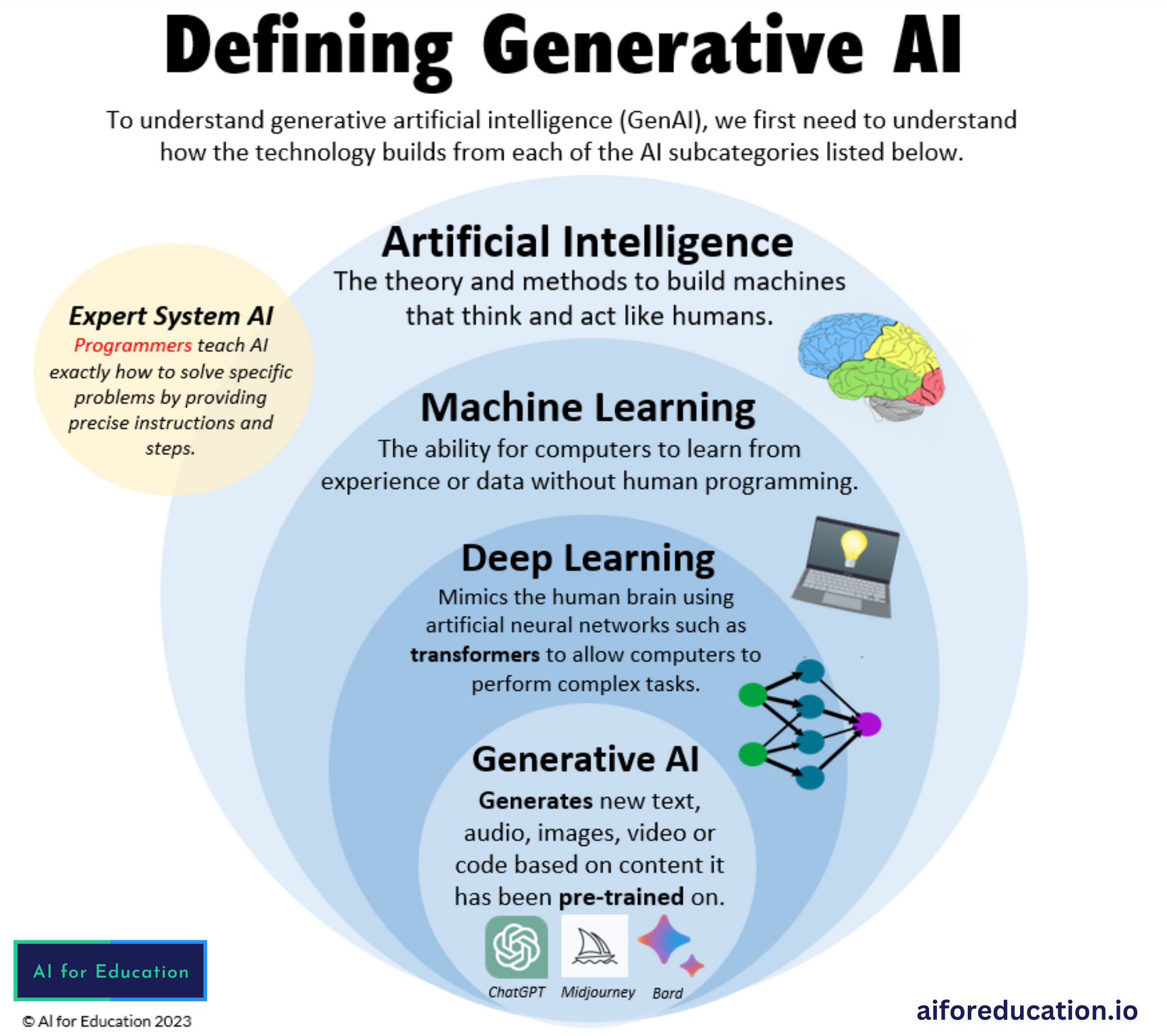
That's why so lots of are executing vibrant and smart conversational AI models that customers can connect with through message or speech. GenAI powers chatbots by understanding and creating human-like message reactions. In addition to client solution, AI chatbots can supplement advertising initiatives and assistance interior interactions. They can likewise be integrated into web sites, messaging apps, or voice aides.
{kind=link}
Latest Posts
Ai In Transportation
What Is The Difference Between Ai And Robotics?
How Does Ai Enhance Video Editing?